Serveur pour la conversion automatisée de grands volumes de documents
Conçu pour la conversion de grands volumes de documents, ABBYY FineReader Server transforme vos larges collections documentaires en archives numériques interrogeables et accessibles. Grâce à une technologie d’OCR et de conversion de pointe, vos documents numérisés et électroniques sont, de manière simple, précise et automatique, convertis en PDF, PDF/A, Microsoft Word et autres formats pour une recherche, une conservation sur le long terme, un travail collaboratif et d’autres traitements.
Convertir les documents en formats accessibles et interrogeables – tels que PDF, HTML et XML – vous permet de stocker des informations électroniques dans votre système informatique, ce qui se traduit par une plus grande efficacité grâce à une récupération plus rapide des données.
ABBYY FineReader Server réceptionne les documents images venant de dossiers partagés en réseau, de scanners, d’emails ou de Microsoft® SharePoint® et les convertit automatiquement en formats numériques interrogeables grâce à la technologie d’OCR (reconnaissance optique de caractères). Si nécessaire, l’utilisateur peut corriger manuellement les informations sous forme de texte et/ou ajouter des métadonnées au document. Les fichiers numériques qui en résultent peuvent être sauvegardés dans autant d’espaces de stockage que souhaité et/ou acheminés vers d’autres applications.
Nouveautés dans FineReader Server :
- Supprimer les métadonnées des fichiers de sortie : utile lorsque les utilisateurs doivent supprimer des données confidentielles avant de publier des documents ou d’archiver des documents.
- Exporter vers le format JSON : les fichiers de sortie JSON contiennent des informations sur le texte reconnu et sa mise en forme.
- Rechercher du contenu à l’aide d’expressions régulières : dans les scénarios d’optimisation d’archivage et de stockage, les utilisateurs peuvent désormais utiliser des expressions régulières dans les flux de travail d’audit pour rechercher des documents dans des archives sélectionnées.
Accélérez et simplifiez de manière significative les processus centraux de l'entreprise
ABBYY FineReader Server convertit automatiquement les documents, avec un minimum d’intervention de la part de l’utilisateur. Il fonctionne en arrière-plan et effectue toutes les étapes du traitement des documents de façon autonome, soit en continu soit à des moments prédéfinis.
Avantages :
- Standardisez vos contenus : Transformez des séries de documents en bibliothèques numériques standardisées et bien organisées.
- Rendez le contenu accessible et consultable : Les utilisateurs peuvent rapidement trouver dans les archives numérisées les documents contenant les mots-clés recherchés.
- Optimisez le traitement des documents : Créez des documents numériques pouvant être facilement stockés, rapidement distribués à des systèmes spécialisés ou partagés entre les équipes.
- Planifiez vos procédures : Vous pouvez choisir de convertir au fil des besoins 24h/24, ou planifier des traitements par lots. Vous optimisez ainsi l’utilisation de votre matériel informatique.
- Donnez le pouvoir aux utilisateurs non-techniciens : FineReader Server ne nécessite pas de formation spécifique ni de connaissances pré-requises pour débuter les procédures de conversion.
- Obtenez un rapide retour sur investissement : Le déploiement de FineReader Server est rapide et sa maintenance est simple, si bien que vous pouvez obtenir plus rapidement d’excellents résultats.
Pour les :
- Moyennes et grandes entreprises ;
- Fournisseurs de services de numérisation ;
- Autorités publiques ;
- Cabinets juridiques et comptables ;
- Entreprises d’ingénierie et de fabrication ;
- Banque et finance ;
- Santé ;
- Centre d’archivages, bibliothèques.


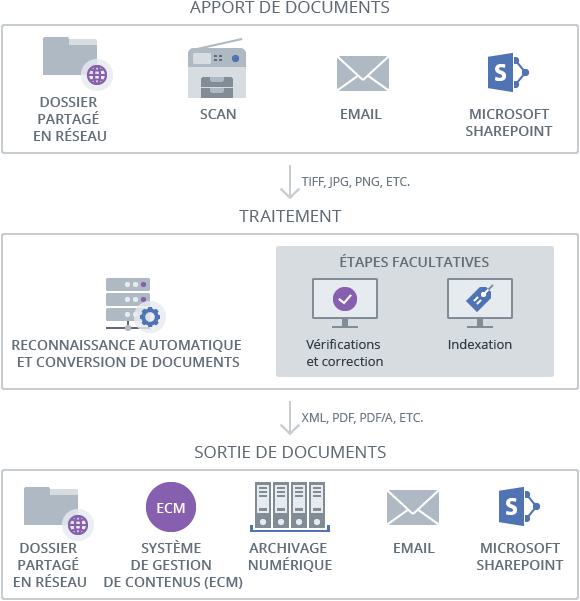
Fonctionnalités
- Une technologie OCR avec la puissance de l’IA : produit des résultats rapides et précis dans plus de 200 langues (caractères européens, arabes, chinois, japonais, coréens, etc.).
- Architecture reposant sur le réseau : utilisez toutes les ressources hardware disponibles, de la façon la plus efficace possible.
- Adaptabilité à de grands volumes : convertit de grands volumes de documents en très peu de temps.
- Technologie PDF modulable : possibilité de compresser les PDF pour réduire la taille des fichiers tout en conservant leur qualité ; prend en charge les formats PDF/A (-1a, -1b, -2a, -2b, -2u, -3a, -3b, -3u), PDF/E, PDF/UA. Prend en charge les signatures numériques et les filigranes.
- Une vaste palette de formats compatibles : convertit automatiquement à partir de fichiers PDF, JPEG, TIFF, Word, Excel, OpenDocument Text, PowerPoint, HTML, et d’autres formats.
- Intégration avec SharePoint : convertit automatiquement en PDF interrogeables les documents issus de bibliothèques SharePoint.
- Reconnaissance des codes-barres : détecte et lit des codes-barres 1D et 2D grâce à l’IA, pour permettre la séparation de documents et/ou l’ajout de métadonnées.
- Types de documents et métadonnées : attribue automatiquement les types et attributions de documents. Permet la création manuelle de métadonnées si nécessaire.
- Reconnaissance des polices historiques : compatible avec les polices Black Letter, Scwabacher et la plupart des polices gothiques en anglais, allemand, français, italien et espagnol.
- Intégration aux systèmes existants : se connecte facilement à des archives numériques ou des systèmes de gestion de contenu d’entreprise, via des tickets XML, des API basées sur la technologie COM et API Web Service, y compris API REST.
- Séparation de documents : sépare automatiquement les documents en fonction du nombre de pages, des pages blanches, des pages avec codes-barres et/ou de règles prédéfinies.
- Rapport d’audit : analyse les archives pour identifier les types de fichiers et le nombre de documents interrogeables, non interrogeables et de doublons.